Learning the basics of Computer Vision
This article is written by Chahat Deep Singh. (chahat[at]terpmail.umd.edu)
Please contact Chahat if there are any errors.
Table of Contents:
1. Introduction
We have seen fascinating things that our camera applications like instagram, snachat or your default phone app do. It can be creating a full structure of your face for facial recognition or simply creating a panorama from multiple images. In this course, we will learn how to recreate such applications but before that we require to learn about the basics like filtering, features, camera models and transformations. This article is all about laying down the groundwork for the aforementioned applications. Let’s start with understanding the most basic aspects of an image: features.
2. Features and Convolution
2.1 What are features?
What are features in Machine vision? Is it similar as Human visual perception? This question can have different answers but one thing is certain that feature detection is an imperative building block for a variety of computer vision applications. We all have seen Panorama Stitching in our smartphones or other softwares like Adobe Photoshop or AutoPano Pro. The fundamental idea in such softwares is to align two or more images before seamlessly stitching into a panorama image. Now back to the question, what kind of features should be detected before the alignment? Can you think of a few types of features?
Certain locations in the images like corners of a building or mountain peaks can be considered as features. These kinds of localized features are known as corners or keypoints or interest points and are widely used in different applications. These are characterized by the appearance of neigborhood pixels surrounding the point (or local patches). Fig. 1 demonstrates strong and weak corner features.

The other kind of feature is based on the orientation and local appearance and is generally a good indicator of object boundaries and occlusion events. (Occlusion means that there is something in the field of view of the camera but due to some sensor/optical property or some other scenario, you can’t.) There are multiple ways to detect certain features. One of the way is convolution.
2.2 Convolution
Ever heard of Convolutional Neural Networks (CNN)? What is convolution? Is it really that ‘convoluted’? Let’s try to answer such questions but before that let’s understand what convolution really means! Think of it as an operation of changing the pixel values to a new set of values based on the values of the nearby pixels. Didn’t get the gist of it? Don’t worry!
Convolution is an operation between two functions, resulting in another function that depicts how the shape of first function is modified by the second function. The convolution of two functions, say and is written is or and is defined as:
Let’s try to visualize convolution in one dimension. The following figure depcits the convolution (in black) of the two functions (blue and red). One can think convolution as the common area under the functions and .
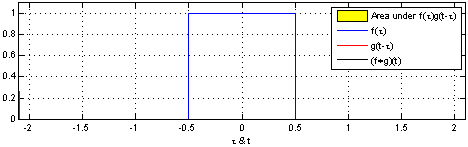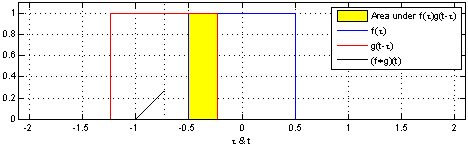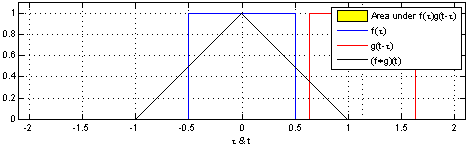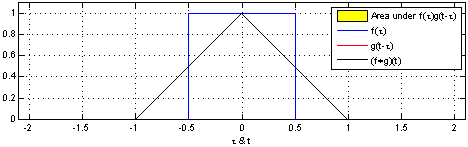
Since we would be dealing with discrete functions in this course (as images are of the size ), let us look at a simple discrete 1D example: and . Let the output be denoted by . What would be the value of ? In order to compute this, we slide so that it is centered around i.e. . We multiply the corresponding values of and and then add up the products i.e. It can be inferred that the function (also known as kernel or the filter) is computing a windowed average of the image.
Similarly, one can compute 2D convolutions (and hence any dimensions convolution) as shown in image below:
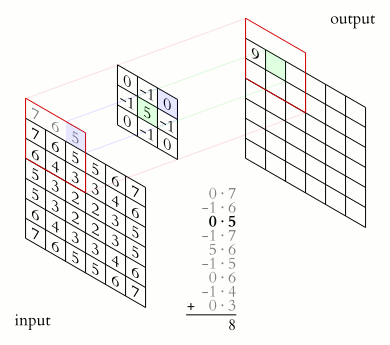
These convolutions are the most commonly used operations for smoothing and sharpening tasks. Look at the example down below:
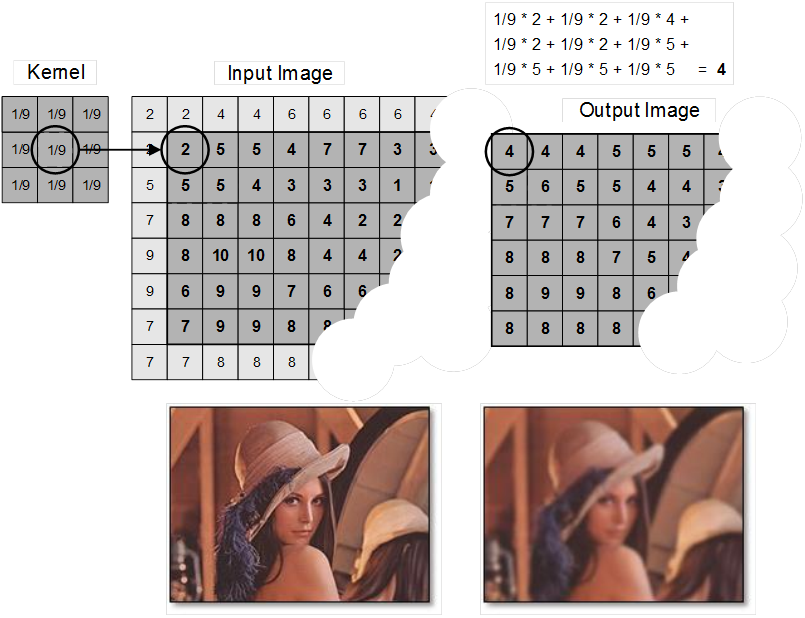
Different kernels (or convolution masks) can be used to perform different level of sharpness:

Apart from the smoothness operations, convolutions can be used to detect features such as edges as well. The figure given below shows how different kernel can be used to find the edges in an image using convolution.

A good explanation of convolution can also be found here.
Deconvolution:
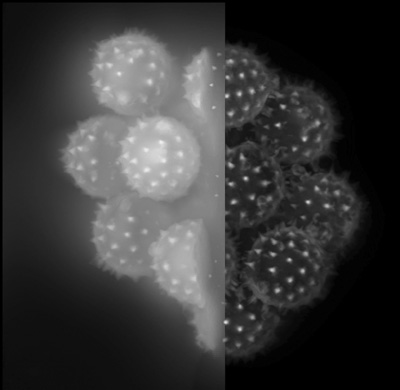
Clearly as the name suggests, deconvolution is simply a process that reverses the effects of convolution on the given information. Deconvolution is implemented (generally) by computing the Fourier Transform of the signal and the transfer function (where ). In frequency domain, (assuming no noise) we can say that: . Fourier Transformation: Optional Read, Video
One can perform deblurring and restoration tasks using deconvolution as shown in figure:
Now, since we have learned the fundamentals about convolution and deconvolution, let’s dig deep into Kernels or point operators). One can apply small convolution filters of size or or so on. These can be Sobel, Roberts, Prewitt, Laplacian operators etc. We’ll learn about them in a while. Operators like these are a good approximation of the derivates in an image. While for a better texture analysis in an image, larger masks like Gabor filters are used. But what does it mean to take the derivative of an image? The derivative or the gradient of an image is defined as: It is important to note that the gradient of an image points towards the direction in which the intensity changes at the highest rate and thus the direction is given by: Moreover, the gradient direction is always perpendicular to the edge and the edge strength can by given by: . In practice, the partial derivatives can be written (in discrete form) as the different of values between consecutive pixels i.e. as and as .
Figure below shows commonly used gradient operators.

You can implement the following in MATLAB using the function edge with various methods for edge detection.
Before reading any further, try the following in MATLAB:
Different Operators:
Sobel Operator:
This operator has two kernels that are convolved with the original image I in order to compute the approximations of the derivatives.
The horizontal and vertical are defined as follows:
The gradient magnitude can be given as: and the gradient direction can be written as: . Figure below shows the input image and its output after convolving with Sobel operator.

Prewitt:
Roberts:
Canny:
Unlike any other filters, we have studied above, canny goes a bit further. In Canny edge detection, before finding the intensities of the image, a gaussian filter is applied to smooth the image in order to remove the noise. Now, one the gradient intensity is computed on the imge, it uses non-maximum suppression to suppress only the weaker edges in the image. Refer: A computational approach to edge detection. MATLAB has an approxcanny function that finds the edges using an approximate version which provides faster execution time at the expense of less precise detection. Figure below illustrates different edge detectors.
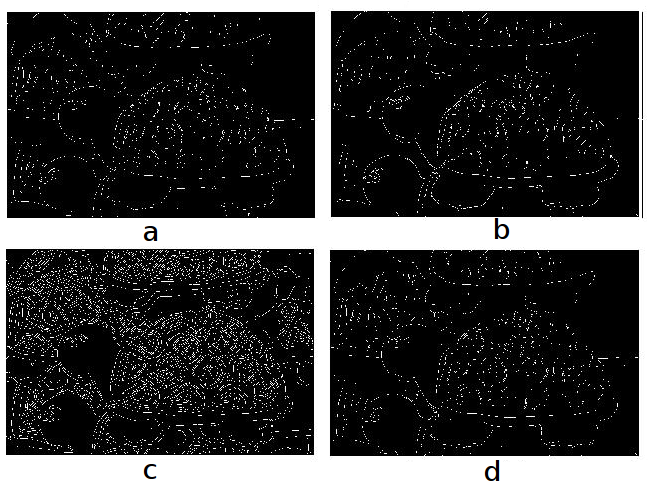
Corner Detection:
Now that we have learned about different edge features, let’s understand what corner features are! Corner detection is used to extract certain kinds of features and common in panorama stitching (Project 1), video tracking (project 3), object recognition, motion detection etc.
What is a corner? To put it simply, a corner is the intersection of two edges. One can also define corner as: if there exist a point in an image such that there are two defintive (and different) edge directions in a local neighborhood of that point, then it is considered as a corner feature. In computer vision, corners are commonly written as ‘interest points’ in literature.
The paramount property of a corner detector is the ability to detect the same corner in multiple images under different translation, rotation, lighting etc. The simplest approach for corner detection in images is using correlation. (Correlation is similar in nature to convolution of two functions). Optional Read: Correlation
In MATLAB, try the following:
corner(I, 'detectHarrisFeatures'): Harris Cornerscorner(I, 'detectMinEigenFeatures'): Shi-Tomasi CornersdetectFASTFeatures(I): FAST: Features from Accelerated Segment Test
